|
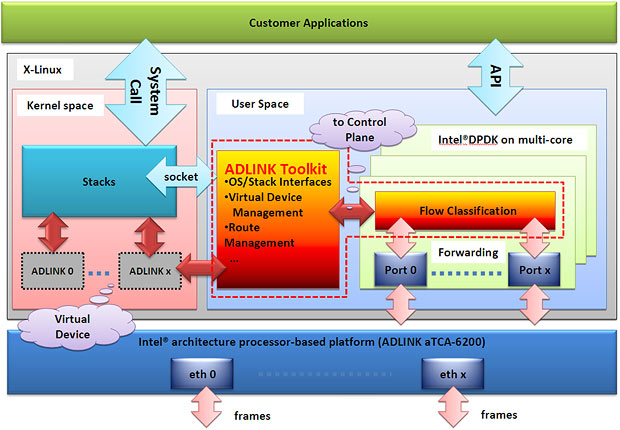
相比原生 Linux(Native Linux)�����,采用Intel® DPDK技術(shù)后能夠大幅提升IP轉(zhuǎn)性能的主要原因在于Intel® DPDK采用了如下描述的主要特征�����。
輪詢模式取代中斷
通常當(dāng)數(shù)據(jù)包進(jìn)入的時(shí)候��,Native Linux會(huì)從網(wǎng)絡(luò)接口控制器(NIC,Network Interface Controller)接收到中斷�����,然后調(diào)度軟中斷�����,對(duì)所得的中斷進(jìn)行上下文切換�����,并喚醒系統(tǒng)調(diào)用�����,如read()和write()����。
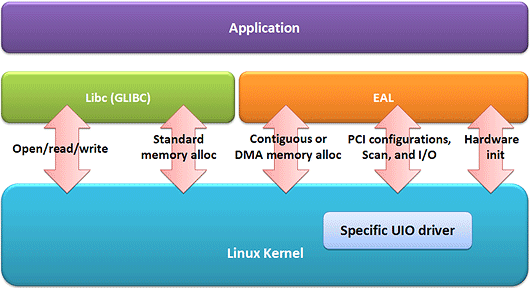
相比之下,Intel® DPDK采用了優(yōu)化的輪詢模式驅(qū)動(dòng)(PMD��,Poll Mode Driver)代替默認(rèn)的以太網(wǎng)驅(qū)動(dòng)程序��,從而可以不斷地接收數(shù)據(jù)包����,避免軟件中斷�����,上下文切換和喚醒系統(tǒng)調(diào)用,從而大大的節(jié)省重要的CPU資源���,并且降低了延遲����。
HugePage取代傳統(tǒng)頁(yè)
相比Native Linux的4kB 頁(yè)���,采用更大的頁(yè)尺寸意味著可以節(jié)省頁(yè)的查詢時(shí)間���,并減少轉(zhuǎn)譯查找緩存(TLB,Translation Lookaside Buffer)丟失的可能�����。
Intel® DPDK作為用戶空間(User-space)應(yīng)用運(yùn)行時(shí)��,在自己的內(nèi)存空間中分配HugePage至存儲(chǔ)幀緩沖區(qū)�,環(huán)形和其他相關(guān)緩沖區(qū)�,這些緩沖區(qū)是由其他應(yīng)用程序控制����,甚至是Linux內(nèi)核。本白皮書描述的測(cè)試中��,總計(jì)1024@2MB的HugePage被保留用于運(yùn)行IP轉(zhuǎn)發(fā)應(yīng)用���。
零拷貝緩沖區(qū)
在傳統(tǒng)的數(shù)據(jù)包處理過(guò)程中����,原生 Linux(Native Linux)解封包的報(bào)頭���,然后根據(jù)Socket ID將數(shù)據(jù)復(fù)制到用戶空間(User Space)緩沖區(qū)���。一旦用戶空間(User Space)應(yīng)用程序完成了數(shù)據(jù)的處理,一個(gè)write()系統(tǒng)調(diào)用將被喚醒并把數(shù)據(jù)送至內(nèi)核����,負(fù)責(zé)將數(shù)據(jù)從用戶空間(User Space)拷貝至內(nèi)核緩沖區(qū),封裝包的報(bào)頭��,最后借助相關(guān)的物理端口將數(shù)據(jù)發(fā)出去�����。顯然,原生 Linux(Native Linux)在內(nèi)核緩沖區(qū)和用戶空間(User Space)緩沖區(qū)之間進(jìn)行拷貝動(dòng)作�,犧牲了很多的時(shí)間和資源。
相比之下��,Intel® DPDK在自己保留的內(nèi)存區(qū)域接收數(shù)據(jù)包���,這個(gè)區(qū)域位于用戶空間(User Space)緩沖區(qū),之后根據(jù)配置規(guī)則將這些數(shù)據(jù)包分類到每一個(gè)Flow中�����。在處理完解封包之后����,在相同的用戶空間(User Space)緩沖區(qū)中使用正確的報(bào)頭進(jìn)行包封裝,最后通過(guò)相關(guān)的物理端口發(fā)送這些數(shù)據(jù)����。
Run-to-Completion(RTC,運(yùn)行到完成)和Core Affinity
在執(zhí)行應(yīng)用之前���,Intel® DPDK會(huì)進(jìn)行初始化���,分配所有的低級(jí)資源��,如內(nèi)存空間��,PCI設(shè)備����,定時(shí)器��,控制臺(tái)����,這些資源將被保留且僅用于那些基于Intel® DPDK的應(yīng)用。初始化完成之后�����,每一個(gè)核(或線程���,當(dāng)BIOS設(shè)置中啟用了Intel®超線程技術(shù)時(shí))將被啟用來(lái)負(fù)責(zé)每一個(gè)執(zhí)行單元����,并根據(jù)實(shí)際應(yīng)用的需求,運(yùn)行相同的或不同的工作負(fù)載���。
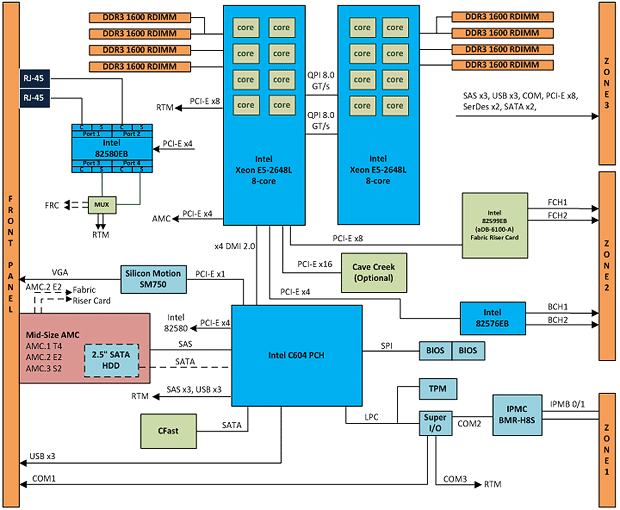
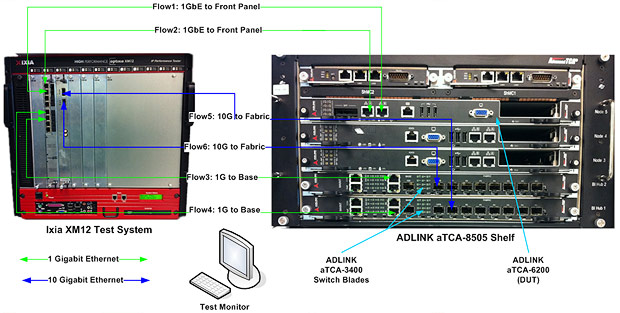
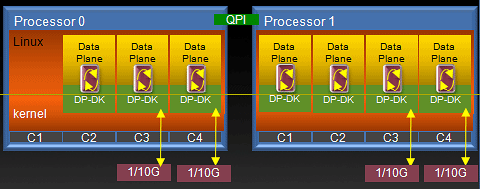
此外��,Intel® DPDK還提供了一種方法��,即可以設(shè)置每個(gè)執(zhí)行單元運(yùn)行在每一個(gè)核心上���,以維持更多的Core Affinity,從而避免緩存丟失��。在此白皮書描述的測(cè)試中�,aTCA-6200處理器刀片的物理端口根據(jù)Affinity被綁定在兩個(gè)不同的CPU線程上。
無(wú)鎖執(zhí)行和緩存校準(zhǔn)
Intel® DPDK提供的庫(kù)和API�,被優(yōu)化成無(wú)鎖����,以防止多線程應(yīng)用程序死鎖現(xiàn)象的發(fā)生。對(duì)于緩沖區(qū)���、環(huán)形和其他數(shù)據(jù)結(jié)構(gòu)�,Intel® DPDK也進(jìn)行了優(yōu)化���,執(zhí)行了緩存校準(zhǔn)�,以達(dá)到緩存行(Cache-Line)的效率最大化,同時(shí)最大限度減少緩存行(Cache-Line)的沖突��。
|